Podríamos decir que casi todo lenguaje de programación usado en la actualidad admite la separación de su código en módulos. No siempre estos módulos son llamados “funciones” y hay sutiles diferencias: por ejemplo, Pascal tiene tanto funciones como procedimientos (estos últimos no tienen un valor de retorno, sino que permiten modificar el valor de sus parámetros), Assembler usa rutinas, en los lenguajes orientados a objetos tenemos métodos (un concepto propio de programación orientada a objetos), Python tiene tanto métodos como funciones.
Una función, en programación, se equipara bastante al concepto de función matemática: toma datos (recordemos que, en una función matemática, se usan una o más variables), hace algo con ellos y arroja un resultado. El detalle acá es que una función en programación podría no arrojar ningún resultado (“void” en Java, “None” en Python, etc.), lo que las diferencia un poco de las funciones matemáticas.
La modularización (es decir, la separación en módulos del código de un programa) permite dividir la solución del problema en partes que pueden ser resueltas por separado. Además, permite realizar fragmentos de código reutilizables: una función puede ejecutarse varias veces con distintos datos. Esto también permite que parte de un algoritmo esté centralizada en un módulo, haciendo más sencillo su mantenimiento.
Ejemplo 1: Supongamos que estamos haciendo un programa para una empresa, cuyo código ocupa unas 5000 líneas y una de las tareas que el programa realiza es calcular los sueldos que la empresa debe pagar a sus vendedores, donde la política de la empresa determina una bonificación del 5% si el vendedor superó los $10000 en ventas durante el mes. Supongamos también que ese cálculo del sueldo aparece en 100 de las 5000 líneas totales que tiene el programa. Si la empresa nos informa que ha cambiado su política interna y que, debido a la inflación, el monto a superar ya no es de $10000 sino de $16000, deberíamos cambiar el dato en las 100 líneas donde se realiza el cálculo. Pero, si el cálculo estuviera hecho dentro de un módulo, podría evitarse escribirlo 100 veces y que, en cada una de esas 100 líneas sólo se invoque al módulo para que realice el cálculo y devuelva el resultado. Entonces, las modificaciones (en este caso, cambiar 10000 por 16000) se hacen una única vez, dentro del módulo, y todo el programa queda actualizado.
Otra ventaja de las funciones es que nos permiten abstraernos de los detalles y concentrarnos en algún algoritmo en particular. Esto sucede, por ejemplo, cuando necesitamos el resultado de alguna operación concreta para usarlo dentro de un algoritmo pero no podemos concentrarnos en cómo se hace esa operación porque estamos enfocados en ese algoritmo que la contiene. Entonces, destinamos una función a resolver dicha operación, teniendo en mente las características del resultado que esa función va a arrojar, y sólo incluimos en el algoritmo general una invocación a esa función. Una vez que tenemos ese algoritmo construido, nos dedicamos a trabajar en la función (ver Abstracción y modularización).
Un detalle a destacar es que una función puede ser llamada (o “invocada”) desde otros módulos, incluso desde otras funciones. Cuando un programa comienza su ejecución, las funciones no se ejecutan en el lugar del código en el que se definen. El compilador o el intérprete sólo las “lee” pero no hace nada al respecto, y busca el punto de inicio del programa (en Python podría ser la primera línea de código que no esté dentro de una función, en Java será la función main()…). Así, las funciones sólo se ejecutan cuando son llamadas.
Para llamar a una función, normalmente se coloca el nombre de ésta, seguido de sus argumentos entre paréntesis. Los argumentos son los datos que se “envían” a la función para que ésta trabaje (esto suele llamarse “pasaje de parámetros”). Por ejemplo, si una función tuviera como tarea sumar dos números y retornar el resultado de la suma, los datos que necesita son los dos números que debe sumar. Esos datos deben enviarse (“pasarse”) a la función, porque los módulos deben interpretarse como algoritmos separados del resto, es decir, debe haber poco “acoplamiento” entre el módulo invocado y el módulo que lo invoca. Inclusive, los módulos podrían no ser siquiera parte del programa que estamos haciendo.
Ejemplo 2: Podría resultar que descarguemos de internet un módulo que algún programador distribuye gratuitamente y lo usemos dentro de nuestro programa, por lo cual ese programador jamás podría haber sabido qué datos usa nuestro programa y qué nombres de variables tiene, por lo que es necesario que le “pasemos” esos datos. El programador sólo usará variables que empiezan y terminan dentro de la función (variables “locales”) y parámetros (dándole los nombres que él cree convenientes) donde luego se van a guardar los valores que se le envíen a la función durante el pasaje de parámetros. Así, si estuviéramos construyendo una función que suma dos números, podríamos decir que vamos a nombrar a esos números como num1 y num2, y el resultado será la suma num1+num2. Si luego la función es llamada con el número 12 y el número 4, en ese orden, entonces num1 tomará el valor 12 y num2 tomará el valor 4.
En muchos lenguajes, incluido Python, las funciones deben definirse antes de que sean invocadas.
Además, debido a la abstracción, sabemos que la invocación a una función “se reemplaza” por su valor de retorno. Entonces, podríamos tener la siguiente función que suma dos números, implementada de la siguiente forma en Python:
def sumarDosNúmeros(num1, num2):
return num1+num2Y podríamos necesitar llamar a esa función para obtener el resultado para luego usar ese resultado de alguna forma que nuestro algoritmo requiera. Por ejemplo, podría ser que queremos guardar el resultado de la suma de 12+4 en una variable, entonces haríamos:
resultado=sumarDosNúmeros(12,4)O bien podríamos querer usar ese resultado como argumento de otra función, como la función print:
print(sumarDosNúmeros(12,4))O tal vez queremos usarlo dentro de una operación matemática, ya que sabemos con certeza que esa función devuelve un dato de tipo numérico:
resultado=sumarDosNúmeros(12,4)**5Como sabemos que el valor de retorno es un dato de tipo numérico, entonces podemos usar la función en cualquier parte del código donde pueda usarse un dato numérico:
if sumarDosNúmeros(12,4) > 0:
#hacer algoPero no siempre los parámetros son valores literales. Podríamos pasar como parámetros variables, expresiones, resultados de otras funciones…
precio=float(input("Precio: $"))
aumento=float(input("Aumento: $"))
print("El precio aumentado es $", sumarDosNúmeros(precio,aumento))Si mantenemos siempre en mente el concepto de abstracción, comprenderemos que, en el último fragmento de código, la función se está invocando con los valores que el usuario haya ingresado y que quedaron almacenados en las variables precio y aumento, y que el valor retornado por la función (la suma precio+aumento) se está pasando como argumento de la función print.
La función print es un perfecto ejemplo de cómo un módulo puede ser hecho de manera totalmente abstracta de forma que podemos usarlo (en este caso, para “imprimir” cosas en la pantalla) sin tener idea de cómo trabaja (a menos que tengamos mucha curiosidad y nos pongamos a investigar cómo hace para imprimir cosas en la pantalla, pero esto no es necesario para utilizar la función).
Parámetros y variables locales y globales
Cuando una función se ejecuta, adquiere un espacio “aparte” (“local”) en la memoria, donde guarda sus parámetros, sus variables locales, su valor de retorno, etc. Al finalizar la ejecución de la función, ese espacio “aparte” se elimina y queda disponible para ser usado por otro módulo u otro programa. Entonces, se hace necesario que la función tenga en ese espacio todos los datos con los que necesita trabajar, y que no deba tomarlos desde “afuera” (en el espacio global a la función).
Cuando una variable pertenece al ámbito local de un módulo, esa variable no existe para el resto de los módulos. Entonces, si una función declara una variable a=0 y luego la usa, pero además el programa principal declara la variable a=100, habrá dos variables con el mismo nombre (“a”) pero en distintos espacios de la memoria (una en el espacio de la función y otra en el espacio del programa principal). No olvidemos que las variables no son más que abstracciones de direcciones de memoria. Entonces, cada vez que en un módulo se usa una variable, primero se buscará si ella existe dentro del espacio local a ese módulo y luego, si allí no se encuentra, se buscará en el ámbito global al módulo.
Ejemplo 3:
def contarDígitos(número):
cantidad=0
while número != 0:
cantidad+=1
número//=10
return cantidad
cantidad=5
for i in range(cantidad):
num=int(input("Contar los dígitos del número..."))
print(contarDígitos(num))En el ejemplo 3, el programa comienza ejecutando desde donde se asigna la variable cantidad=5 y luego se pide al usuario el ingreso de números para que la función retorne cuántos dígitos tiene y este resultado sea impreso en pantalla. Pero la función también tiene una variable local llamada cantidad, pero esta no es la misma variable que utiliza el programa principal, sino que refrencia a otra dirección de memoria: una propia de la función.
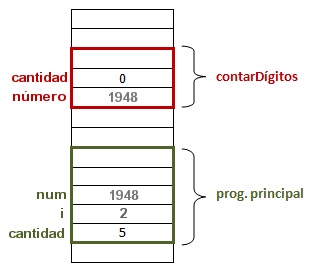
En esta vista de la memoria se está ejecutando la tercera iteración del for (ya que la variable i vale 2) y el usuario ingresó el número 1948, el cual se pasó como argumento a la función.
De todas maneras, varios lenguajes permiten que en las funciones se usen variables globales: esto es, variables que no están dentro del espacio local a la función y que pertenecen a otros módulos o al programa principal. Pero esto, a pesar de estar permitido, no es considerado una “buena práctica de programación”.
El problema de usar variables globales es que, a la larga, en un programa grande (y donde tal vez trabajan más de un programador simultáneamente), el código se hace inmantenible: es difícil predecir cuál será el estado de esa variable en cada punto de la ejecución (lo cual hace que sea difícil probar y buscar errores en ese código) y, además, es difícil de interpretar el código de cada función por separado porque hay que estar viendo en qué estado está o qué contiene esa variable global antes de poder analizar una función que la usa.
Otro inconveniente que podría surgir en programas que requieren un alto rendimiento es que las variables globales son más lentas: al buscar en la memoria el valor de una variable, siempre se comienza por el espacio local al módulo que la usa y, si no encuentra allí la variable, entonces pasa al ámbito del módulo que lo contiene, y así hasta llegar al ámbito superior.